Microsoft Research Institute described its application of deep learning and deep neural networks to different scenarios in the Tutorial of IJCAI 2016. The second part mentioned the application of deep learning in statistical machine translation and conversation. This article is part 3—Selected Continuous expression of natural language processing tasks.
Joint compilation: Blake, Zhang Min, Chen Chun

Select continuous expression of natural language processing tasks
l Deep Semantic Similarity Model (DSSM) for Information Retrieval and Personal Sorting
l Intensive reinforcement learning in a continuous semantic natural language processing task environment
l Multiple semantic learning and reasoning for subtitles and visual questions

Continuous semantic representation of natural language learning, for example: from the original statement to an abstract semantic vector

Sent2Vec is very important in many natural language processing tasks. It can handle issues including web search, ad selection, text sorting, online recommendation, machine translation, knowledge architecture, question answering, personalized recommendations, image search, icon annotations, and more.

Supervision issues:
although
l The text semantics that need to be learned are hidden
l There is no clear target learning model
l Also I do not know how to reverse transmission?
But luckily
l We generally know if two texts are "similar"
l This is the signal of semantic expression learning

Deep architecture semantic model
Depth Architecture Semantic Model/Deep Semantic Similarity Model transforms the entire sentence into a continuous semantic space. For example: sentence becomes vector
DSSM builds on character (non-vocabulary) for its scalability and universality
DSSM is trained to optimize similar drive objects
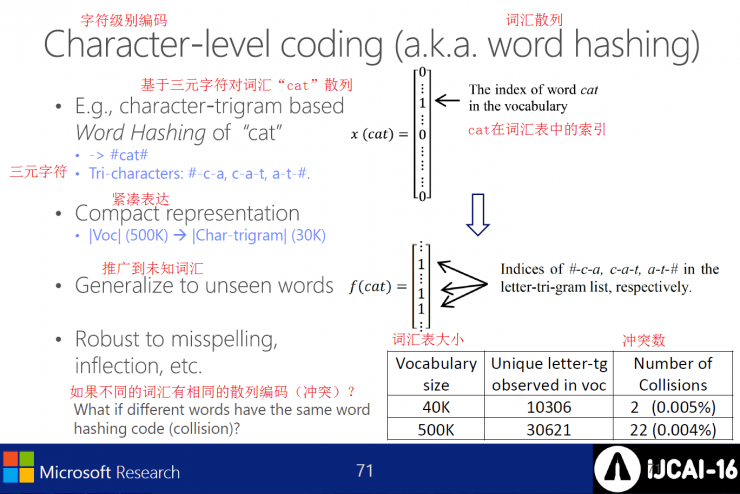
Encode at the character level, which is a lexical hash.

The DSSM established at the character level breaks down any vocabulary into a series of related characters and tends to handle large-scale natural language tasks.

DSSM: A Similar Driving Sent2Vec Model
Initialization: neural networks are initialized with random weights
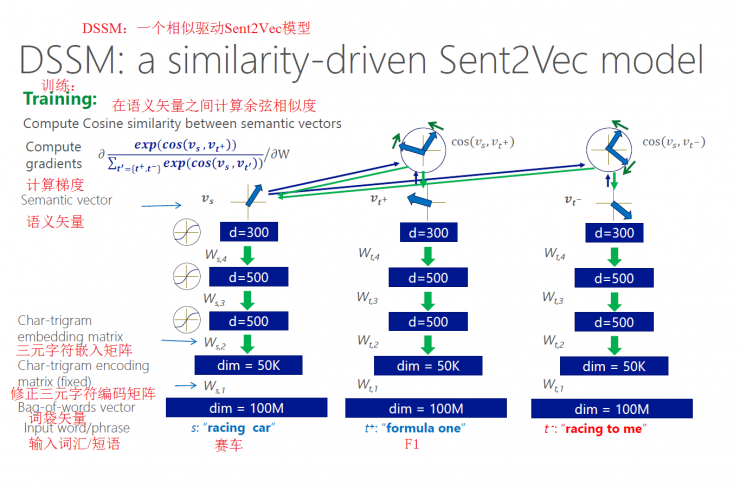
Training: Computing cosine similarity between semantic vectors
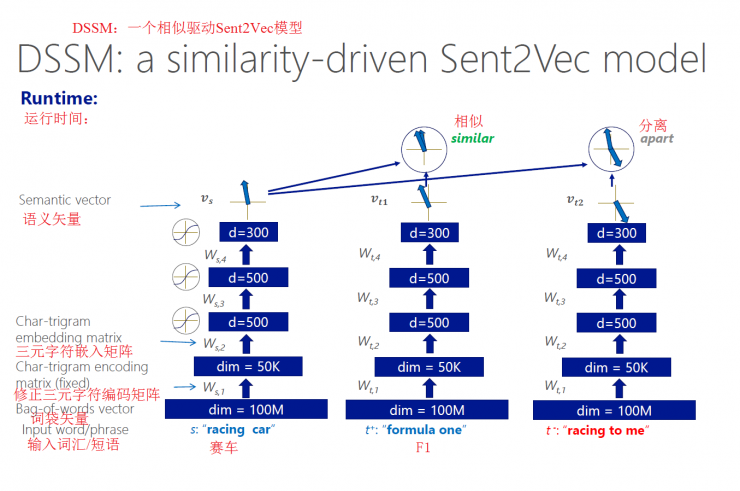
operation hours

Training objective: loss based on cosine similarity
Use web search as an example:
Query q with a series of documents D
Goal: The possibility of clicking on a document after a given query

Using Curl Neural Networks in DSSM
Modeling local texts at the curl layer
Modeling Global Text at the Convergence Layer
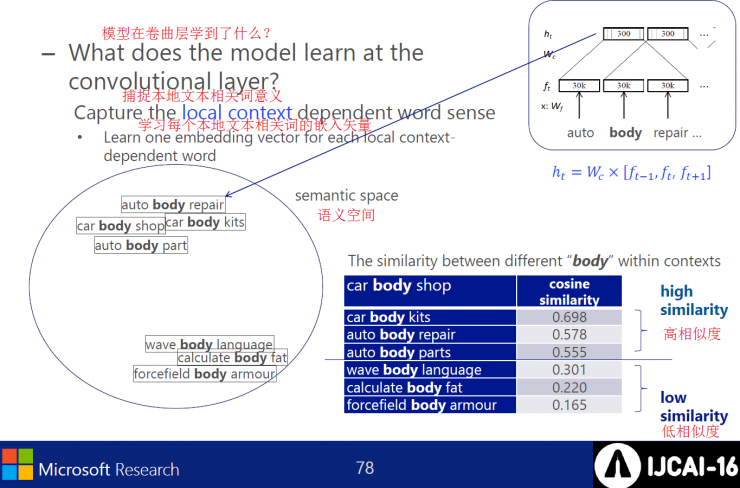
The model captures the meaning of the relevant words of the local text in the curl layer and learns the embedded vector of each local text related word.

CDSSM: What happened at the largest convergence layer?
Aggregate local themes to form a global
Identify the major words/phrases of the largest aggregation layer
Obtaining the most active neuron vocabulary at the largest aggregation layer

For the DSSM of the learning search, the training dataset searches for semantically relevant text groups in the records.

Experiment settings
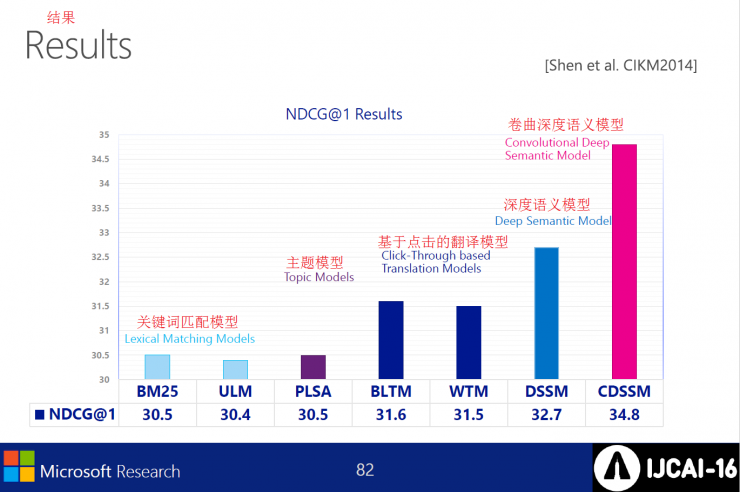
The curl depth semantic model achieves the best result.
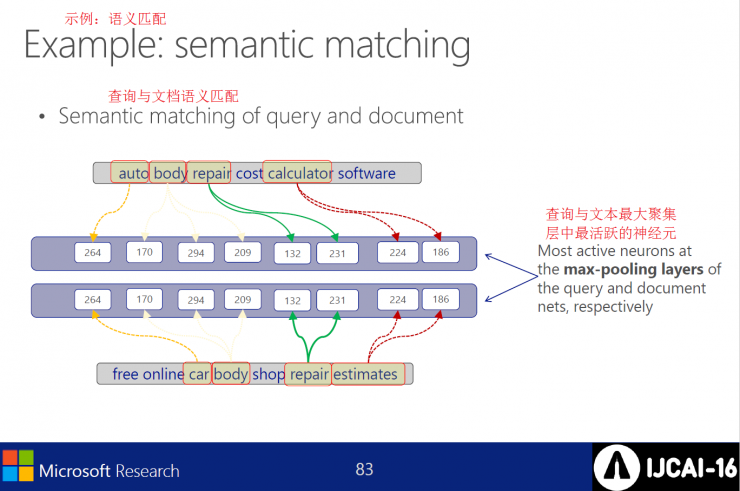
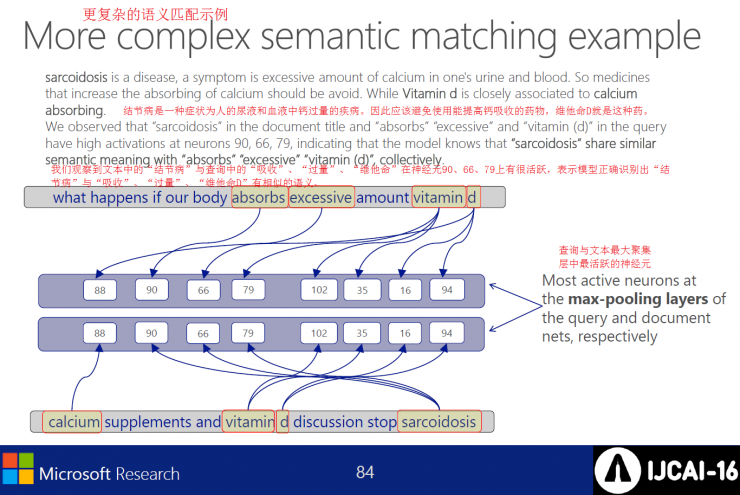
Semantic matching example

Convolution DSSM:
Convolution hidden layers are coded one after the other
The hidden layer semantically encodes the entire sentence in the last vocabulary
Training models with cosine similar driving goals


Use long-term short-term memory (LSTM) results:
LSTM learns much faster than regular RNN
LSTM can effectively represent semantic information using vector sentences
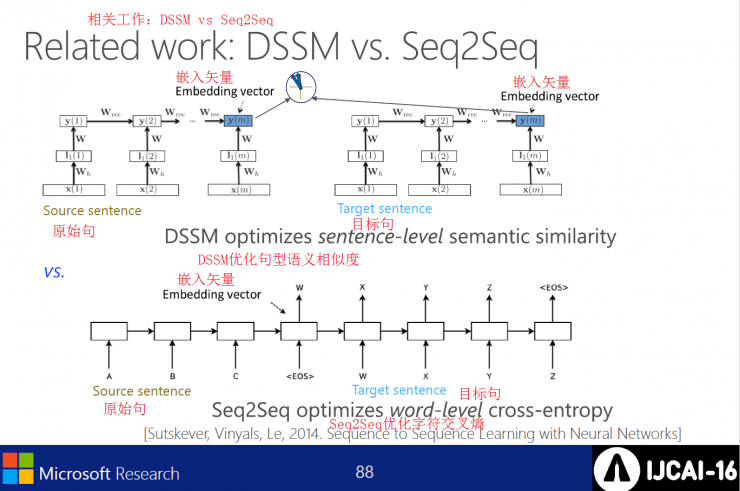
DSSM vs. Seq2Seq

Give a special user's article span representing interest entities and look for entity supplements.

Learn Contextual Entity Order of DSSM

Extract tag pairs from web browsing logs, hyperlinks to Wikipedia P`, anchor text for P's in H, environmental vocabulary, text

Contextual entity search - experiment setup:
1. Training/verification data is 18M user clicks on wiki page
2. Evaluate the data: First sample the 10k webpage file as the source file, then use the named entity in the document as the query; third, keep 100 return files as the target file, and finally manually mark whether each target file can be well described entity. There are a total of 870k pairs.
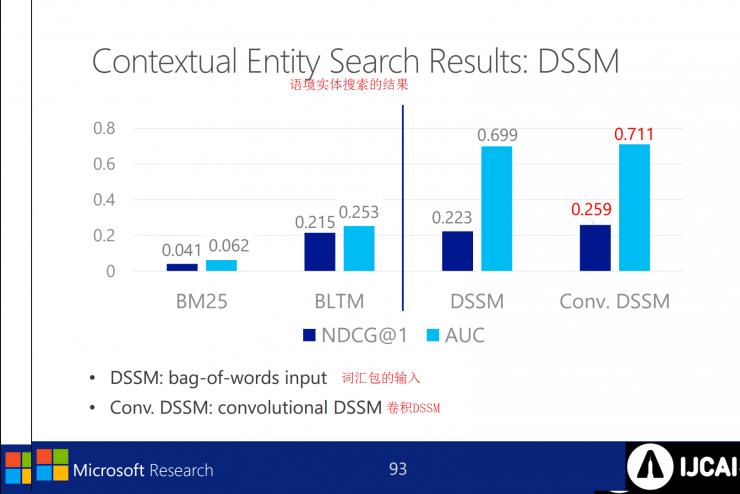
Contextual entity search results

Some related work:
Depth CNN text input (the main grading task in the article)
Sequence-to-sequence learning; paragraph vector (learning paragraph vector)
Recursive NN (tree structure like decomposition)
Tensor product representation (tree representation)
Tree Structure LSTM Network (Tree Structure LSTM)

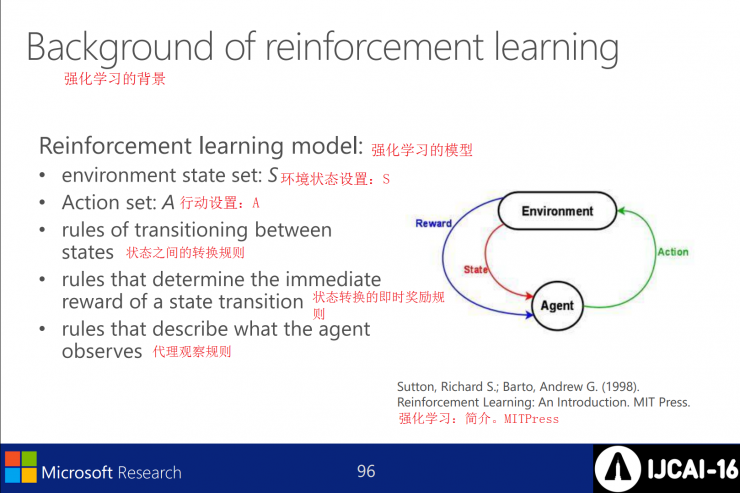
Reinforcement learning models - including environmental status settings S; action settings A, and transition rules between states; instant reward rules and agent observation rules for state transitions.

Q-learning is a policy for learning RLs (rules that an agent must follow when selecting actions for a given current state). Its purpose is to find the optimal policy of MDP by learning an action-value function, aka. Q-function: Used to calculate the expected utility of actions taken after the training has converged.

Recent Achievements: The Deep Q Network achieved human-level performance when playing five Atari games. The convolutional neural network is used to compute Q(s,a) and utilizes a large action space, ignoring the small action space.

Recent Achievements (continued): Robot AlphaGO defeated the world Go champion. It is similar to the deep Q network setting, ignoring the small action space. Two CNNs (policy and value networks) are established in its model.

Enhanced learning of language understanding: states and actions are described in the form of text strings, and agents act accordingly through text strings (correctly maximizing long-term rewards). Then, the state of the environment is changed to a new state, and the agent is also rewarded instantly.

The action space and the state space are very large, and the characteristics of the action are determined by the unbounded neural language description.

In the NLP mission, the characteristics of the action space are determined by the neural language, which is discrete and nearly borderless. We propose a deep reinforcement related network to plan both state and space into a continuous space, where the Q-function is the correlation function of the state vector and the behavior vector.
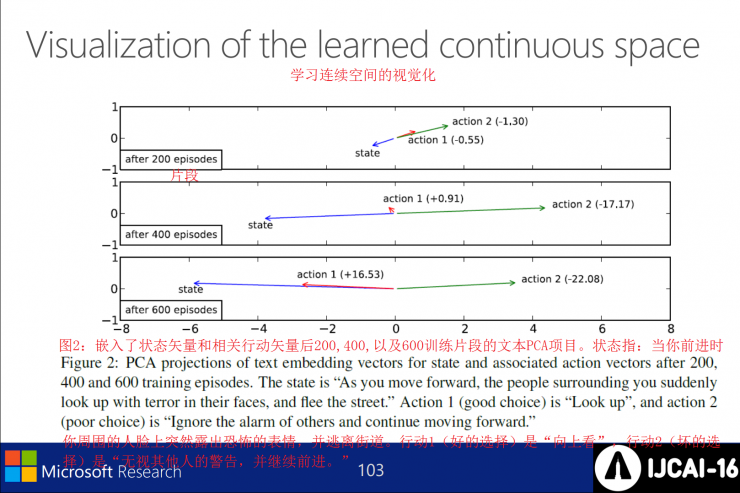
To learn the visualization of the continuous space, Figure 2 shows the text PCA project of 200,400,600 training segments after the embedded state vector and related action vectors. State means: When you move forward. People around you have a horrified expression on their faces and flee the streets. Action 1 (good choice): Look up, Action 2 (bad choice): Disregard others' warnings and move on.

DRRN and DQN test results on two text games (learning curve)

The table shows sample values ​​of the aggregated Q function, and DRNN is a good summary of the unseen behavior.

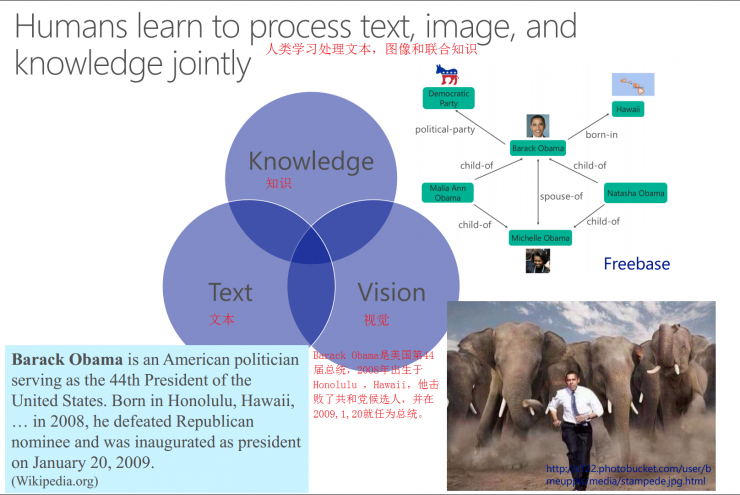
Humans learn to process texts, images, and joint information.
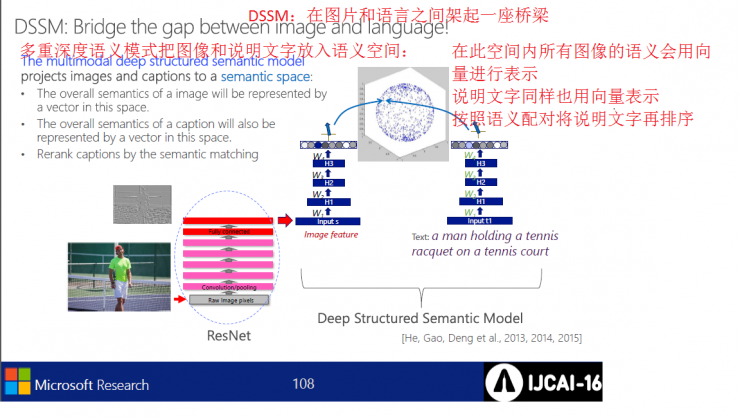
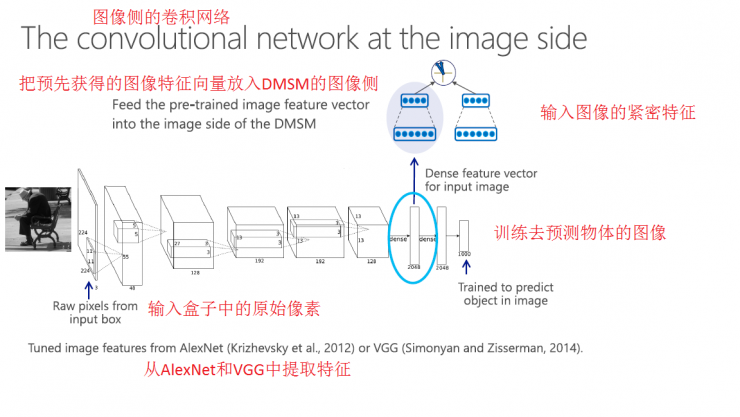
Image-side convolutional network implementation process
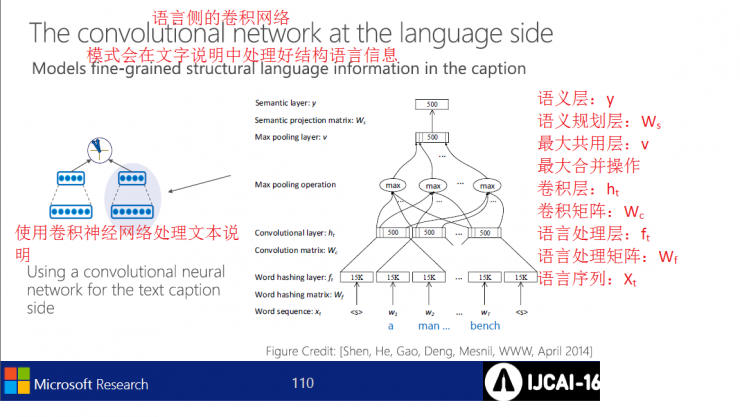
Language-side convolutional network implementation process

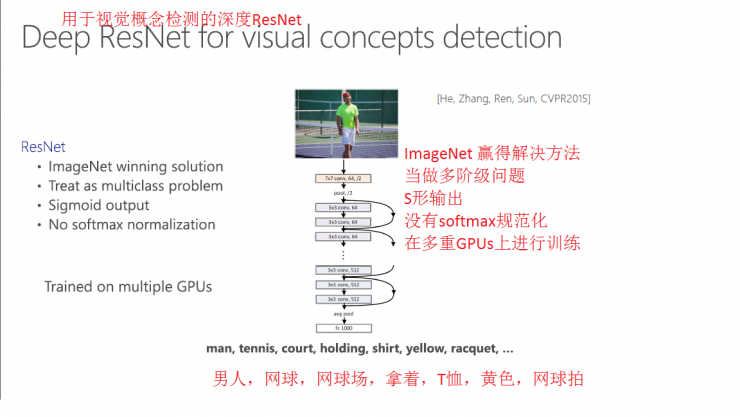


The image shows that the MELE detects the key concepts in the image through the deep learning mode, and the MELE generates an interpretation from the image detection. After detecting words, they are rearranged to form sentences.
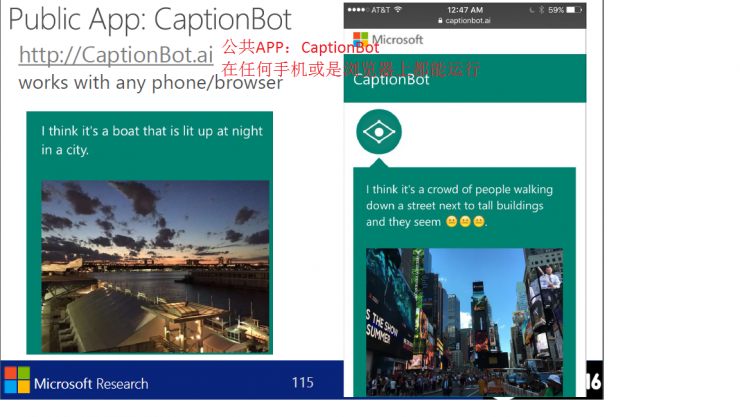

CaptionBot sample

Explanation to the process of answering questions

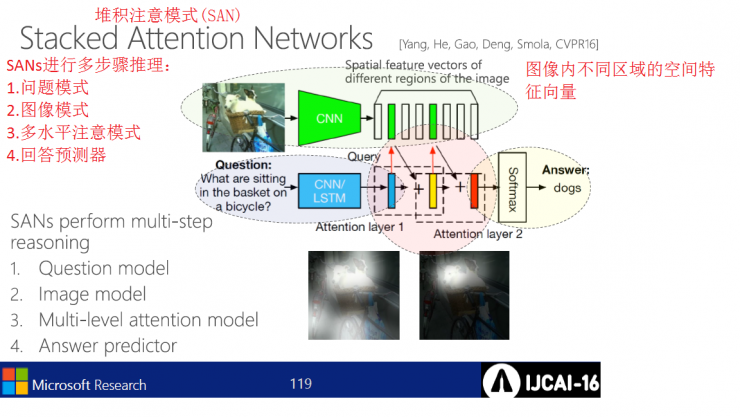
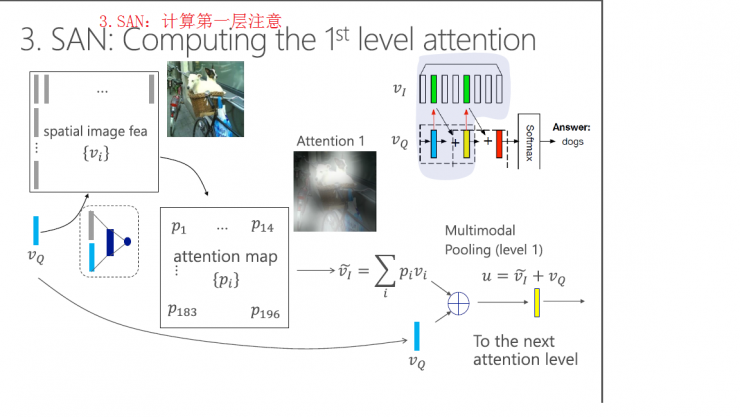
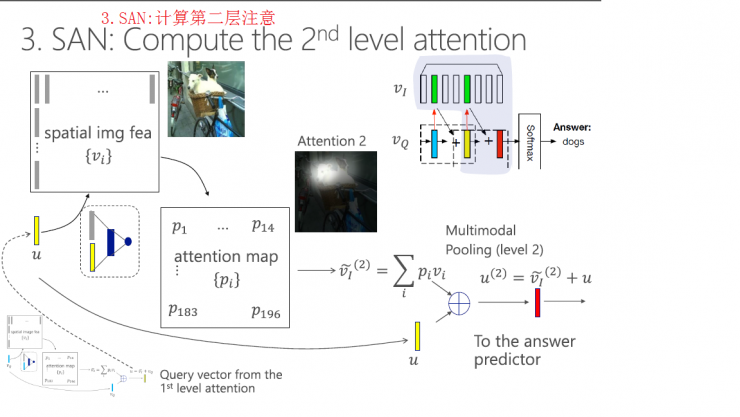
Stacked attention mode inference engineering: problem mode, image mode, multi-level attention mode, answer predictor.
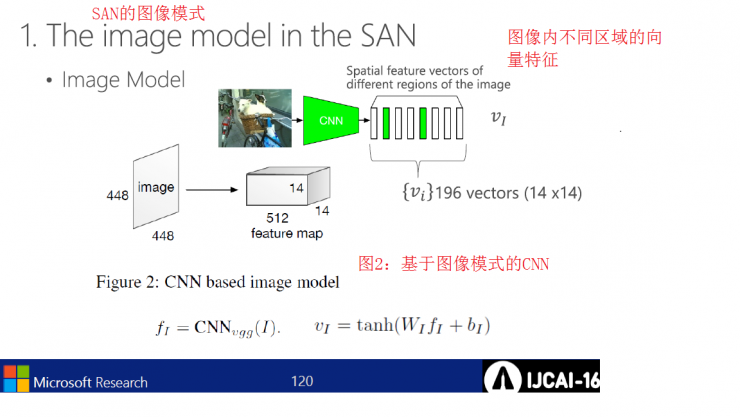
SAN image mode

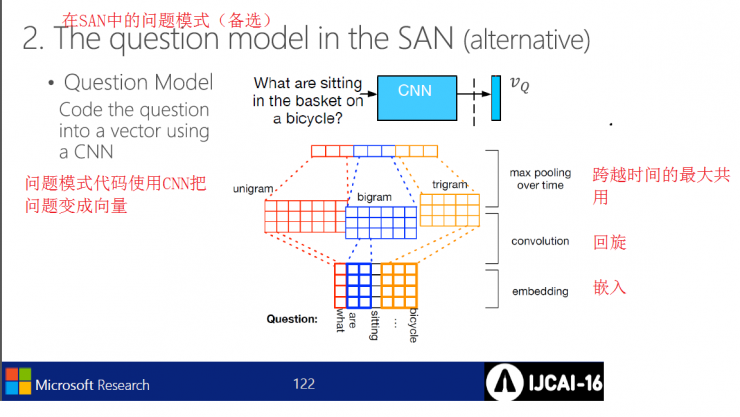
Problem model in SAN

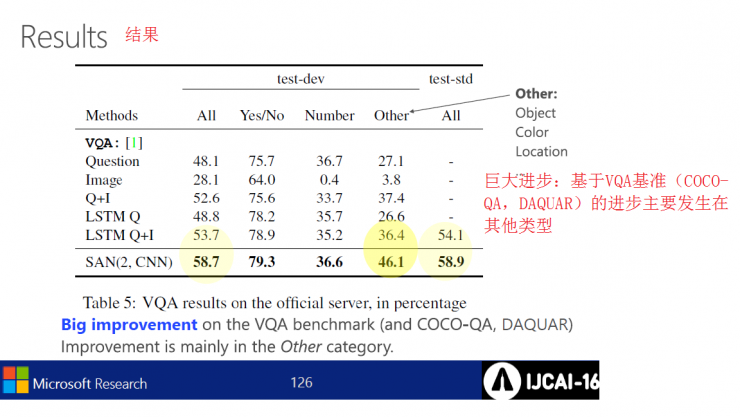

Answer example

to sum up:
This section mainly introduces concepts such as learning Sent2Vec through DSSM, strengthening learning of NLP tasks in continuous space, and visual language joint expression learning. Specifically include:
Learn Sent2Vec with DSSM:
DSSM places the entire sentence in a continuous space
Create DSSM based on feature character level
DSSM directly optimizes the semantic similarity of objective function
Intensive learning of NLP tasks in continuous space:
Use deep neural networks to put states and actions (determined by borderless NL) into continuous semantic space
Calculating Q Functions in Continuous Semantic Spaces
Visual language joint expression learning:
Image Interpretation - CaptopnBot Sample
Visual Question Answer - The Key is Reasoning
PS : This article was compiled by Lei Feng Network (search “Lei Feng Network†public number) and it was compiled without permission.
Via Microsoft IJCAI2016