The ranking of GoRatings, the world’s professional Go ranking website, shows that Ke Jie, the world’s top ranked player for 24 consecutive months, has been overtaken by Google’s artificial intelligence robot AlphaGo. As of today, AlphaGo topped the world with 3612 points, surpassing all human players.
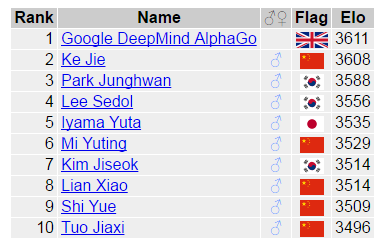
As shown in the above figure, currently Google Deepmind AlphaGo ranks first in the world with 3611 points, Ke Jie ranks second in the world with 3608 points, and Li Cheshi, a Korean chess player who previously suffered a “human-machine war†with AlphaGo with 1:4, is ranked 3557. fourth.
According to the rules of the Goratings World Go Ranking, if a newly added player wins only, it cannot be counted as an official ranking. AlphaGo had just lost a set of Li Shishi, which gave AlphaGo the opportunity to be ranked in the rankings, and has been ranked second in the world. In addition, the Goratings rule requires that both sides have played against each other, and if the opponent's points change, their points will be adjusted accordingly. AlphaGo had previously defeated Li Shishi with 4 wins and 1 loss. Therefore, as long as Li Shishi’s points increase, AlphaGo will also follow suit. The reason why Ke Jie's ranking dropped was because of the poor performance of Jin Libei's cross-strait world championships competition. Victory Zhou Junxun, negative Shi Yue and Tang Weixing, this gave AlphaGo the opportunity to be called the world's number one.
At this point, AlphaGo topped the world with 3612 points, surpassing all human players. This makes us wonder why what makes AlphaGo so different is that it can be the first player in all Go AIs and even defeat the top of the human world.
In the just-convened IJCAI2016 (25th International Conference on Artificial Intelligence) academic conference, Google DeepMind researcher David Sliver, one of the heroes behind AlphaGo, published a book titled " Mastering the Game Using Deep Neural Networks and Tree Search." "Inspired by Deep Neural Networks and Tree Search ". In the speech, he mainly explained the realization principle of AlphaGo and analyzed the results of AlphaGo and human chess players.

In the speech he mentioned that AlphaGo mainly improved the following two methods
l MCTS Search (Monte Carlo Tree Search)
l CNN (Curl Neural Network)

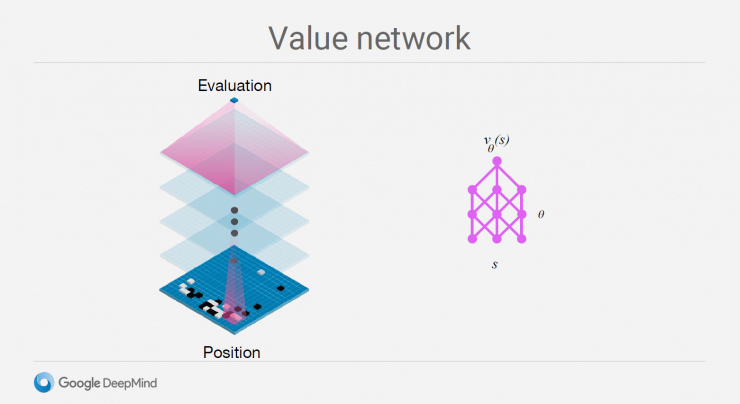
Value Networks and Policy Networks:
Value Networks evaluates the board position, and Policy Networks chooses to play chess. These neural network models are trained in a new way, combined with supervised learning learned by human expert competitions, as well as in self-play secondary schools. The essence of reinforcement learning is the combination of the deep learning network (CNN) and the Monte Carlo search tree (MCTS).
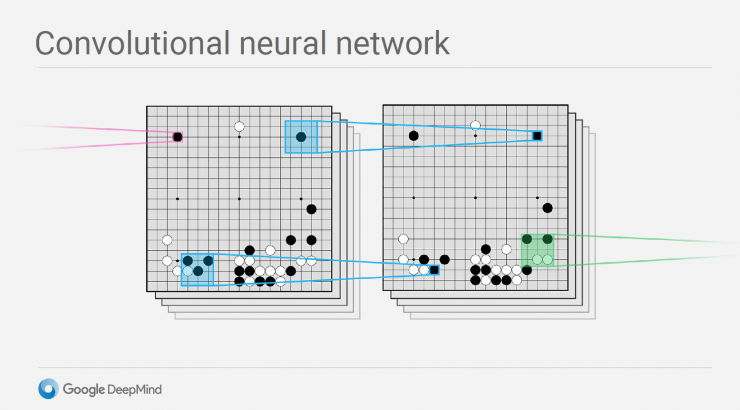
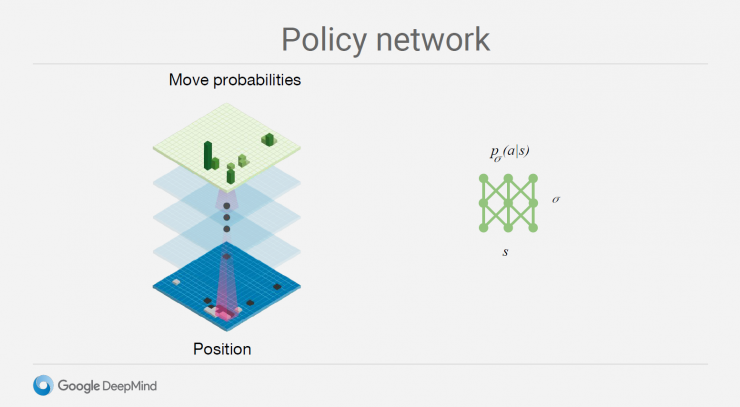
Based on global features and the strategy network trained by the deep convolutional network (CNN), its main role is to give the current state of the disk as input, and output the probability of the next move of the chess on the other open space of the chessboard.
Another is a fast rollout strategy that is trained using local features and a linear model. The strategy network has a slower speed but higher precision.


Supervised learning on strategic networks
l 12-layer crimped neural network
l Use Google Cloud to train for more than 50 GPUs for four weeks
l 57% accuracy on the test data set (currently best 44%)
Reinforcement learning on strategic networks
l 12-layer crimped neural network
l Use Google Cloud to train a week of events on more than 50 GPUs
l 80% result compared to supervised learning, amateur 3 levels
The strategy network interacts with the previously trained strategy network, using enhanced learning to modify the parameters of the strategy network, and finally obtain an enhanced strategy network.
The implementation process is as follows:
Use an ordinary strategy network to generate the first U-1 step of the game (U is a random variable belonging to [1,450]), and then use random sampling to determine the position of the Uth step (this is to increase the diversity of the game, Prevent overfitting).
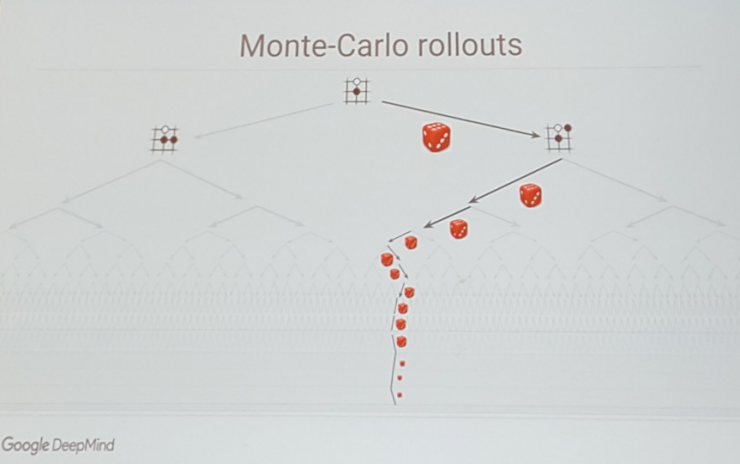
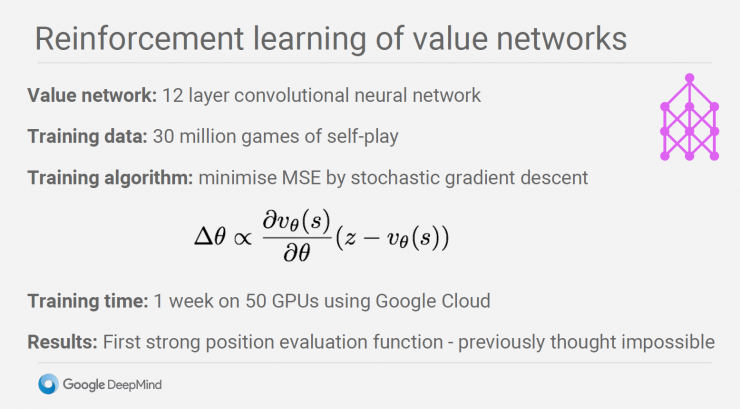
Then, using the enhanced strategy network to complete the process of self-followed by the game until the end of the game to distinguish the winner. After that, the disk in the first step is used as a feature input, and the winner and the loser are labeled. A value network is learned to determine the probability of winning or losing the result. Value network is actually a big innovation of AlphaGo. The most difficult part of Go is that it is difficult to judge the final result based on the current situation. This is also difficult to master for professional players. Through a large amount of self-play, AlphaGo generated 30 million chess games to train the value network. However, due to Go's search space is too large, 30 million chess game can not help AlphaGo completely overcome this problem.
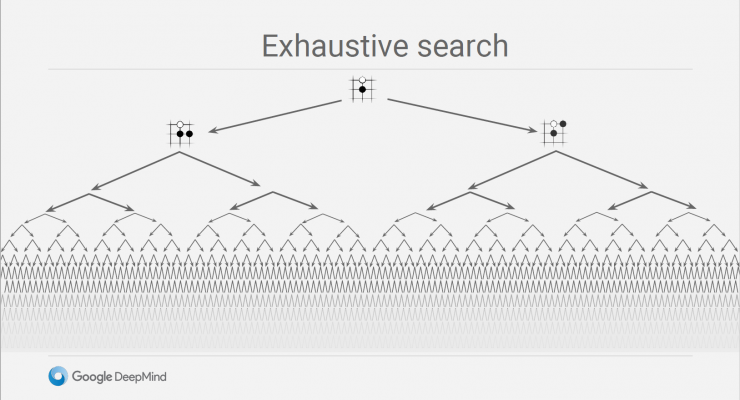
A key aspect of AlphaG is the in- depth neural network embedded in the Monte Carlo Search Tree (MCTS) to reduce the search space, which greatly reduces unnecessary search steps and significantly improves the winning ratio through value networks and strategic networks.

Use strategy network to reduce its width
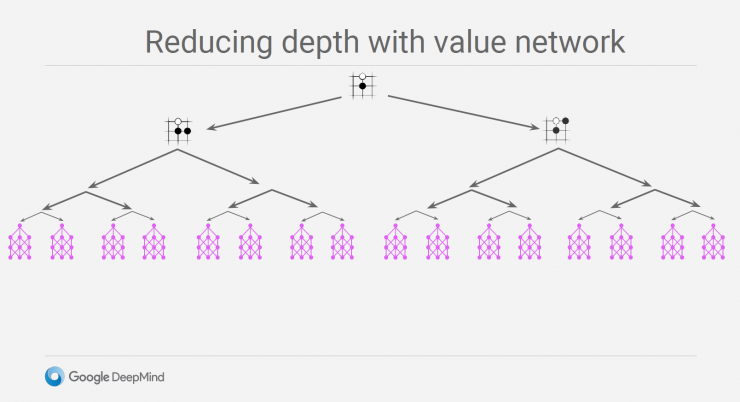
Use value network to reduce depth
Using the two improved networks to judge the situation separately, the scores of the two situations add up to the score at which the last game was won. The fast move strategy used here is a method of using the speed to exchange the quantity. Starting from the position to be judged, the game moves quickly to the end. After each move, there will be a winning or losing result, and then the corresponding winning rate of this node is comprehensively counted. The value network can directly evaluate the final results based on the current status. Both have their advantages and disadvantages and complement each other.
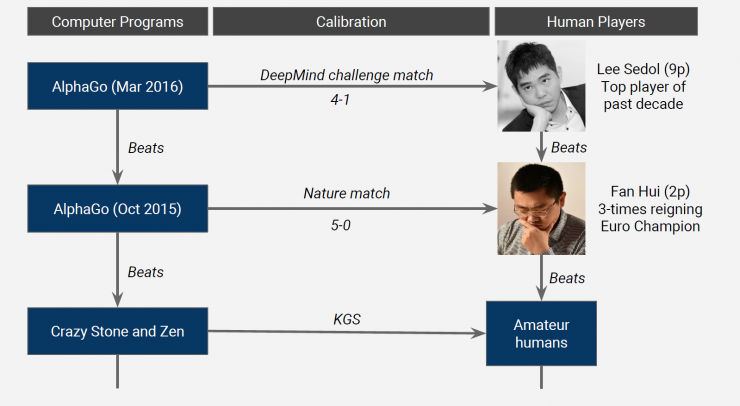
After the 5:0 victory over European Go game champion Fan Li (3rd European Go Championship) in October 2015, AlphaGo beat Korean legendary player Li Shishi (one of the top chess players in the last ten years) in March 2016 at 4:1. In the fourth game, due to Li Shishi's "one hand of God," AlphaGo lost and gave AlphaGo the opportunity to be ranked in the ranking of Goratings.

According to David Silver, AlphaGo has surpassed all other Go AI programs. In the process of playing against Seoul with Li Shishi, he believes that AlphaGo has already demonstrated a level beyond the professional nine-segment player. The ranking based on the Goratings score should be close to 4,500 points. This score not only exceeds the highest score of Chinese player Ke Jie's 9th Division but also is higher than his current score. Whether this amazing achievement is true or not, let us look forward to the ultimate " man-machine war " between AlphaGo and Ke Jie.
Reference materials
PS : This article was compiled by Lei Feng Network (search “Lei Feng Network†public number) and it was compiled without permission.
Via David Silver IJCAI2016