Speech recognition is based on speech. Through speech signal processing and pattern recognition, the machine automatically recognizes and understands the spoken language of human beings. Speech recognition technology is a high-tech technique that allows a machine to transform a speech signal into a corresponding text or command through a recognition and understanding process. Speech recognition is a cross-disciplinary subject with a wide range of disciplines. It is closely related to the disciplines of acoustics, phonetics, linguistics, information theory, pattern recognition theory, and neurobiology. Speech recognition technology is gradually becoming a key technology in computer information processing technology. The application of voice technology has become a competitive emerging high-tech industry.
1. The basic principle of speech recognition
The speech recognition system is essentially a pattern recognition system, including three basic units of feature extraction, pattern matching, and reference pattern library. Its basic structure is shown in the following figure:
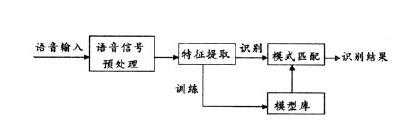
The unknown voice is converted into an electrical signal by the microphone and then added to the input end of the recognition system. First, the pre-processing is performed, then the speech model is established according to the characteristics of the human voice, the input speech signal is analyzed, and the required features are extracted. Create a template for speech recognition. In the process of recognition, the computer compares the voice template stored in the computer with the characteristics of the input voice signal according to the model of speech recognition, and finds a series of optimal matching with the input voice according to a certain search and matching strategy. template. Then according to the definition of this template, the recognition result of the computer can be given by looking up the table. Obviously, this optimal result has a direct relationship with the choice of features, the quality of the speech model, and the accuracy of the template.
2. History and current status of speech recognition technology
In 1952, Davis et al. of AT&TBell Labs developed the first voice-enhanced system with ten English digits. Audry system. In 1956, Olson and Belar of the RCA Laboratory of Princeton University in the United States developed 10 singles. A system of syllable words that uses spectral parameters obtained by a bandpass filter bank as speech enhancement features. In 1959, Fry and Denes attempted to construct a phoneme to 4 vowels and 9 consonants, and used spectrum analysis and pattern matching to make decisions. This greatly improves the efficiency and accuracy of speech recognition. Since then, computer speech recognition has received the attention of researchers from various countries and has begun to enter speech recognition research. In the 1960s, the Soviet Union's MaTIn et al. proposed endpoint detection of speech end points, which led to a significant increase in speech recognition levels; Vintsyuk proposed dynamic programming, which is indispensable for later recognition. The important achievements in the late 1960s and early 1970s were the signal linear prediction coding (LPC) technology and dynamic time warping (DTW) technology, which effectively solved the feature extraction and unequal length speech matching of speech signals. Vector quantization (VQ) and hidden Markov model (HMM) theory. The combination of speech recognition technology and speech synthesis technology enables people to get rid of the constraints of the keyboard. Instead, it is a convenient, natural and user-friendly input method for voice input. It is gradually becoming a key technology for human-machine interface in information technology.
3. Method of speech recognition
At present, representative speech recognition methods mainly include dynamic time warping technology (DTW), hidden Markov model (HMM), vector quantization (VQ), artificial neural network (ANN), and support vector machine (SVM).
Dynamic TIme Warping (DTW) is a simple and effective method for speech recognition in non-specific people. Based on the idea of ​​dynamic programming, the algorithm solves the problem of template matching with different pronunciation lengths. It is a speech recognition technology. An earlier, more commonly used algorithm appears. When applying the DTW algorithm for speech recognition, the pre-processed and framing speech test signals are compared with the reference speech templates to obtain the similarity between them, and the similarity between the two templates is obtained according to a certain distance measure. And choose the best path.
Hidden Markov Model (HMM) is a statistical model in speech signal processing. It is evolved from Markov chain, so it is a statistical recognition method based on parametric model. Because the pattern library is the best model parameter with the highest probability of matching with the training output signal through repeated training instead of the pre-stored pattern sample, and the likelihood probability between the speech sequence to be recognized and the HMM parameter is used in the recognition process. The optimal state sequence corresponding to the maximum value is used as the recognition output, so it is an ideal speech recognition model.
Vector QuanTIzaTIon is an important signal compression method. Compared with HMM, vector quantization is mainly used in speech recognition of small vocabulary and isolated words. The process is to form a vector of a plurality of speech signal waveforms or characteristic parameters into a vector and perform overall quantization in a multi-dimensional space. The vector space is divided into several small areas, each of which finds a representative vector, and the vector that falls into the small area during quantization is replaced by this representative vector. The design of vector quantizer is to train a good codebook from a large number of signal samples, find a good distortion measure definition formula from the actual effect, design the best vector quantization system, and calculate the distortion with the least amount of search and calculation. Achieve the largest possible average signal to noise ratio.
In the actual application process, people also studied a variety of methods to reduce complexity, including memoryless vector quantization, memory vector quantization and fuzzy vector quantization.
Artificial neural network (ANN) is a new speech recognition method proposed in the late 1980s. It is essentially an adaptive nonlinear dynamics system that simulates the principles of human neural activity, with adaptability, parallelism, robustness, fault tolerance and learning characteristics, its powerful classification ability and input-output mapping capability. Very attractive in speech recognition. The method is an engineering model that simulates the human brain thinking mechanism. It is contrary to HMM. Its classification decision-making ability and ability to describe uncertain information are universally recognized, but its ability to describe dynamic time signals is not satisfactory. The MLP classifier can only solve the static pattern classification problem and does not involve the processing of time series. Although scholars have proposed many structures with feedback, they are still not sufficient to characterize the dynamic characteristics of time series such as speech signals. Since the ANN cannot describe the temporal dynamic characteristics of the speech signal well, the ANN is often combined with the traditional recognition method to utilize the respective advantages for speech recognition to overcome the shortcomings of the HMM and the ANN. In recent years, significant progress has been made in the identification algorithm combining neural network and implicit Markov model. The recognition rate is close to the identification system of implicit Markov model, which further improves the robustness and accuracy of speech recognition.
Support vector machine (SVM) is a new learning machine model that applies statistical theory. It adopts Structural Risk Minimization (SRM), which effectively overcomes the shortcomings of traditional empirical risk minimization methods. Taking into account the training error and generalization ability, it has many superior performances in solving small sample, nonlinear and high-dimensional pattern recognition, and has been widely applied to the field of pattern recognition.
4. Classification of speech recognition systems
The speech recognition system can be classified according to the restrictions on the input speech. If the correlation between the speaker and the recognition system is considered, the recognition system can be classified into three categories: (1) a specific person speech recognition system. Only consider the recognition of the voice of a person. (2) Non-specific person voice system. The recognized speech has nothing to do with people, and the recognition system is usually learned by a large number of different people's speech databases. (3) Multi-person identification system. The voice of a group of people can usually be recognized, or become a specific group of speech recognition systems that only require training of the voices of the group of people to be identified.
If you think about the way you talk, you can also classify the recognition system into three categories: (1) Isolated word speech recognition system. The isolated word recognition system requires a pause after entering each word. (2) Connective speech recognition system. The conjunction input system requires a clear pronunciation of each word, and some legatos begin to appear. (3) Continuous speech recognition system. Continuous speech input is a natural, fluent continuous speech input with a large number of legato and accent.
If the vocabulary size of the recognition system is considered, the recognition system can also be divided into three categories: (1) Small vocabulary speech recognition system. A speech recognition system that typically includes dozens of words. (2) A medium vocabulary speech recognition system. An identification system that typically includes hundreds of words to thousands of words. (3) Large vocabulary speech recognition system. A speech recognition system that typically includes thousands to tens of thousands of words. With the improved computing power of computer and digital signal processors and the accuracy of recognition systems, the classification system is constantly changing according to the vocabulary size. It is currently a medium vocabulary recognition system and may be a small vocabulary speech recognition system in the future. These different limitations also determine the difficulty of the speech recognition system.
5, the application of speech recognition
The areas in which speech recognition can be applied are broadly divided into five categories:
Office or business system. Typical applications include: filling out data forms, database management and control, keyboard enhancements, and more.
Manufacturing: In quality control, the speech recognition system provides a “hands-free†and “no-eye†prosecution (component inspection) for the manufacturing process.
Telecommunications: A fairly wide range of applications are available on dial-up telephone systems, including the automation of attendant assistance services, international and domestic remote e-commerce, voice call distribution, voice dialing, and classified ordering.
Medical: The main application in this area is the generation and editing of professional medical reports by sound.
Others: including games and toys controlled and operated by voice, voice recognition systems that help people with disabilities, and voice control for non-critical functions such as on-board traffic control systems and sound systems.

In the future, with the miniaturization and even wearability of handheld devices, various smart glasses and watches will emerge in an endless stream. Of course, it is important to find a market breakthrough. Good solutions and system design references are also essential.
Small computer system interface (SCSI) is an independent processor standard for system level interfaces between computers and intelligent devices (hard disks, floppy drives, optical drives, printers, scanners, etc.). SCSI is an intelligent universal interface standard.
HPCNS SCSI Section
ShenZhen Antenk Electronics Co,Ltd , https://www.antenk.com