The fundamental purpose of speech recognition research is to develop a machine with auditory function, which can directly accept people's oral command, understand people's intentions and make corresponding reflections. The research of speech recognition system involves many subject areas such as microcomputer technology, artificial intelligence, digital signal processing, pattern recognition, acoustics, linguistics and cognitive science. It is a multidisciplinary and comprehensive research field. In recent years, the rapid development of high-performance digital signal processing chip DSP (Digital Signal Process) technology has provided the possibility of real-time implementation of speech recognition. Among them, AD digital signal processing chip has good cost performance and code portability. It is widely used in various fields. Therefore, we use AD's fixed-point DSP processing chip ADSP2181 to realize the recognition of speech signals.
1 Basic process of speech recognition
This article refers to the address: http://
According to the actual application, the speech recognition system can be divided into: identification of specific people and non-specific people, recognition of independent words and continuous words, small vocabulary and large vocabulary, and identification of infinite vocabulary. But regardless of the speech recognition system, its basic principles and processing methods are generally similar. A schematic diagram of a typical speech recognition system is shown in Figure 1.
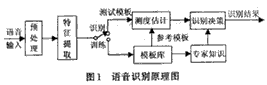
The speech recognition process mainly includes preprocessing of voice signals, feature extraction, and pattern matching. Preprocessing includes pre-filtering, sampling and quantization, windowing, endpoint detection, pre-emphasis, and the like. The most important part of speech signal recognition is feature parameter extraction. The extracted feature parameters must meet the following requirements:
(1) The extracted feature parameters can effectively represent the voice features and have good distinguishability;
(2) There is good independence between the parameters of each order;
(3) The feature parameters should be calculated conveniently, and it is better to have an efficient algorithm to ensure real-time implementation of speech recognition.
In the training phase, after the feature parameters are processed, a model is created for each term and saved as a template library. In the identification stage, the speech signal passes through the same channel to obtain the speech feature parameters, generates a test template, matches the reference template, and uses the reference template with the highest matching score as the recognition result. At the same time, the accuracy of recognition can be improved with the help of a lot of prior knowledge.
2 system hardware structure
2.1 Features of the ADSP2181
AD company's DSP processing chip ADSP2181 is a 16b fixed-point DSP chip, which has large internal storage space, strong computing power and strong interface capability. Has the following main features:
(1) Harvard structure, external 16.67MHz crystal oscillator, command cycle is 30ns, command speed is 33MI / s, all orders are executed in a single cycle;
(2) On-chip integrated 80 kB of memory: 16 kB word (24b) program memory and 16kB word (16b) data memory;
(3) There are three independent computing units: arithmetic logic unit (ALU), multiply accumulator (MAC) and barrel shifter (SHIFT), wherein the multiply accumulator supports multi-precision and automatic unbiased;
(4) A 16b internal DMA port (1DMA) for high-speed access to on-chip memory; an 8b bootstrap DMA (BDMA) port for loading data and programs from the bootloader memory;
(5) 6 external interrupts, and priority or masking can be set.
Due to the above characteristics of the ADSP2181, the system composed of the chip is small in size, high in performance, low in cost and power consumption, and can better implement the speech recognition algorithm.
2.2 System hardware structure
When constructing the speech recognition circuit, we adopt the master-slave structure design method of ADSP2181, and the program is loaded by the CPU through the IDMA port. The hardware structure of the speech recognition system is shown in Figure 2.
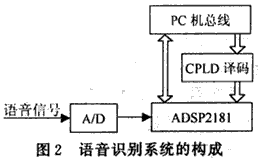
In this configuration, the PC is the main CPU, the ADSP2181 is the slave CPU, and the PC loads the program into the internal memory of the ADSP2181 through the IDMA port. The PC bus is decoded by the CPLD to form control signals such as IRD, IWR, IAL, and IS, and is connected to the IDMA port of the ADSP2181. In this way, when the ADSP2181 is running at full speed, the host can query the running status of the slave and access all the program memory and data memory in the ADSP2181. This brings great convenience to the compilation and debugging of the program and the real-time processing of the voice signal.
3 DSP implementation technology for speech recognition
3.1 Fixed point implementation of floating point arithmetic
There are many floating point operations in the speech recognition algorithm. The use of fixed-point DSP to implement floating-point operations is a problem that needs to be solved first in the preparation of speech recognition programs. This problem can be achieved by the number scaling method. The scaling of the number is to determine the position of the decimal point in the fixed point number. The Q notation is a commonly used calibration method. Its representation mechanism is:
When the set number of points is J and the floating point number is ) /, the conversion relationship between the fixed point number and the floating point number represented by the Q method is:
Floating point number / converted to fixed point number x: x = (int) y × 2Q;
The fixed point number z is converted to a floating point number y: y = (float) x × 2-Q.
3.2 Processing of data precision
When the speech recognition algorithm is implemented by the 16b fixed-point DSP, although the running speed of the program is improved, the data precision is relatively low. This may result in an incorrect operation result due to the accumulated error of the intermediate process. In order to improve the accuracy of data calculation, the following processing methods are used in the program:
(1) Extended accuracy
Where the accuracy requirements are relatively high, the calculated intermediate variables are represented by 32b or even 48b. In this way, the accuracy of the operation is greatly improved when the number of instructions is not increased much.
(2) Using pseudo floating point method to represent floating point numbers
The pseudo floating point method uses the mantissa + exponent method to represent floating point numbers. At this time, the mantissa of the data block can adopt the Q1.15 data format, and the index of the data block is the same. This method of representing data has a large enough data range to fully meet the requirements of data precision, but it is necessary to write a set of exponential and mantissa operations, which will increase the number of instructions and the amount of operations of the program, which is not conducive to real-time implementation.
Both of the above methods can improve the accuracy of the operation, but in actual operation, we must weigh the consideration according to the requirements of the system and the complexity of the algorithm.
3.3 Maintenance of variables
In high-level languages, there are differences between global variables and local variable storage, but in DSP programs, all declared variables are allocated to the data space when linked. So if you define local variables as high-level languages, you will waste a lot of DSP storage space, which is obviously unreasonable for fixed-point DSPs with tight data space. In order to save storage space, it is best to maintain a variable table when writing DSP programs. When entering a DSP submodule, do not rush to allocate new local variables. Priority should be given to variables that have been allocated but not used. Only assign new local variables when they are not enough.
3.4 loop nested processing
Many of the implementations of speech recognition algorithms are implemented in loops. For the processing of loops, you need to pay attention to the following issues:
(1) In the ADSP2100 series DSP chip, the loop nesting can not exceed 4 loads at most, otherwise stack overflow will occur, and the program will not execute correctly. However, in DSP programs for speech recognition, nested programs, including interrupts, often exceed four. At this time, you can't use the do...unTIl... command provided by DSP. You can only design some loop variables yourself and maintain these variables yourself. Since the loop stack of the DSP is not used at this time, it does not cause a stack overflow. In addition, if you use the jump instruction to jump out of the loop instruction, you must maintain the pointers of the three stacks of PC, LOOP and CNTR.
(2) Minimize the number of instructions in the loop. Within the multi-loop, reducing the number of instructions helps to reduce the number of executions of the program. This is beneficial to reduce the execution time of the program and improve the real-time operation.
3.5 Adopt modular programming method
In the implementation of the speech recognition algorithm, in order to facilitate the design and debugging of the program, a modular programming method is adopted. Modules are divided based on the basic process of speech recognition. Each module is divided into several sub-modules, and then programmed and debugged by modules. Before writing the program, first perform algorithm simulation for each module in a high-level language, and then write the assembler based on this. When debugging, you can use the debugging mode of high-level language and assembly language. This can verify the correctness of assembly language by tracking the intermediate state of high-level language and assembly language, and find and correct errors in time to shorten the programming cycle. In addition, in the process of writing the program, the necessary comments and instructions should be added to the key parts to enhance the readability of the program.
In the total adjustment, it is necessary to set the corresponding population parameters and exit parameters in each module, and maintain the stack pointer and intermediate variables.
3.6 Mixed programming with C and assembly language
Nowadays, most DSP chips support mixed programming of assembly language and C or C++ language, and ADSP2181 is no exception. Developing DSP programs in C language has the advantages of shortening the development cycle and reducing the complexity of the program. However, the execution efficiency of the program is not high, and additional machine cycles are added, which is not conducive to the real-time implementation of the program. For this reason, we use the fixed-point processing technique when writing speech recognition algorithms in C language. The ADSP2181 is a 16-bit fixed-point processor. The following issues should be noted in the fixed-point processing:
(1) ADSP2181 supports both decimal and integer operations. In the calculation, the decimal method should be selected so that the absolute value of the calculation result is less than 1;
(2) Replace the floating-point library of C language with a double-word fixed-point operation library to improve the operation precision;
(3) Note that the saturation operation is performed after each multiplication and addition operation to prevent overflow and underflow of the result;
(4) A group of data after loop processing may have different indexes, which are to be normalized so that the subsequent fixed-point operations deal with the exponent and mantissa parts separately.
4 Conclusion
The speech recognition system composed of fixed-point DSP chips has broad application prospects. When writing speech recognition algorithms, it is fixed-point processing and some principles and methods have practical guiding significance for other similar algorithms. In practical applications, it should be noted that the algorithm is optimized according to the characteristics of the DSP chip, so that the performance of the DSP chip is fully exerted.
Flip Wall Clock has been one of the best selling collection among those Flip Clock series.
Unique selling points:
Our flip Wall Clock usually has different designs and shapes in our collection, the unique selling points is their unique designs and clock function, it's not traditional clocks with clock hand and read time by the pointer, it's a unique clock with time showed in number card, like the scoreboard, it's well-functioned, keeps good time, and eco-friendly. You'll not miss this special timepiece for your home.
Handmade timepiece:
Since it's almost handmade clock, especially the number cards that are fixed one piece by one piece by hand, to fix the PVC card into the small hole to keep it well function, our workers must be very careful with handling the number cards and pay attention to the numbers orders;
How to fix a flip clock:
If the clock falls down on the ground, it may cause number cards fall out from the hole, but just take it easy, find the correct position of the number and fix it to the right hole carefully, then the clock will go back to normal again.
Flip Wall Clock
Flip Wall Clock,Black Flip Wall Clock,Wall Hanging Clock,Clock Wall Decoration
Guangzhou Huanyu Clocking Technologies Co., Ltd. , http://www.mid-light.com